
IBM 和彭博社周四宣布,KServe 将加入 LF AI & Data Foundation ,作为其最新的孵化项目。 KServe 提供 Kubernetes 自定义资源定义,用于在任意框架上提供机器学习模型,并支持包括 Watson Assistant 在内的多个 IBM 产品。
Bloomberg、Google、IBM、Nvidia、Seldon 和其他组织与 KServe 项目社区合作,将其作为开源发布和发布。
在博客文章中,IBM 的 Animesh Singh 和 Bloomberg 的 Dan Sun 和 Alexa Griffith 表示,他们代表 KServe 社区发言,并吹捧 LF AI & Data Foundation 的工作“建立一个生态系统以维持人工智能和数据开源项目的创新。”
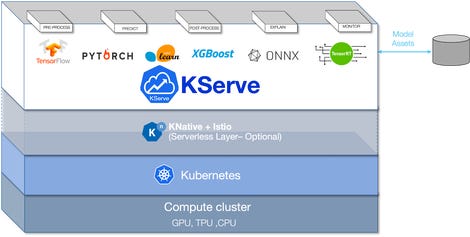
据两家公司称,KServe 旨在通过为 TensorFlow、XGBoost、Scikit-learn、PyTorch 和 ONNX 等常见 ML 框架提供高性能、高度抽象的接口来解决生产模型服务用例。
“KServe 封装了自动缩放、网络、健康检查和服务器配置的复杂性,为您的 ML 部署带来了 GPU 自动缩放、缩放到零和 Canary 推出等尖端服务功能。它为生产提供了一个简单、可插入和完整的故事ML Serving,包括预测、预处理、后处理和可解释性,”Singh、Sun 和 Griffith 说。
IBM 首席技术官兼 Watson AI 总监 Animesh Singh 表示,该公司既是 KServe 的联合创始人,也是采用者。 Singh 表示,数十万个模型同时运行用于互联网规模的 AI 应用程序,例如 IBM Watson Assistant 和 IBM Watson Natural Language Understanding。
此外: IBM 拆分 100 天后,Kyndryl 与 AWS 签署战略云协议
Singh 补充说,IBM 的 ModelMesh 是开源的,可作为 KServe 项目的一部分使用,它解决了昂贵的容器管理挑战,有效地允许他们在单个生产部署中以最小的占用空间运行数十万个模型。
Nvidia 加速计算产品管理高级总监 Paresh Kharya 解释说,Nvidia Triton 推理服务器与 KServe 同步工作,通过其无服务器推理框架封装了 Kubernetes 中 AI 部署和扩展的复杂性。
“Nvidia 继续积极参与 KServe 开源社区项目,以支持轻松大规模部署 AI 机器学习模型,”Kharya 说。
据彭博社人工智能工程负责人 Anju Kambadur 称,KServe 还在帮助彭博社扩大其在彭博终端和其他企业产品中对人工智能的使用。 Kambadur 解释说,Bloomberg 希望快速从构思到原型再到生产,并且需要确保模型在构建后无缝演变以适应数据的变化。
“这不仅对于更快地构建更好的产品很重要,而且对于确保我们释放 AI 研究人员的创造潜力而不用编写大量样板代码给他们带来负担。在这方面,我既兴奋又感激 KServe,它布隆伯格帮助创建并领导了发展,取得了这样的进步,”坎巴杜尔说。

LF 人工智能与数据基金会
流行的韩国搜索引擎 Naver Search 的软件工程师 Mark Winter 补充说,KServe 使他们能够对其 AI 服务基础设施进行现代化改造,并提供处理昼夜循环之间流量扩展差异所需的工具。
“通过在 Knative 和 Kubernetes 之上提供标准化接口,KServe 使我们的 AI 研究人员能够专注于创建更好的模型并将他们的辛勤工作投入生产,而无需成为交付和管理高可用性后端服务的专家,”Winter 说。
该公告是在 KServe 0.8 发布之前发布的,一位发言人表示,该版本将具有新的 ServingRuntime 自定义资源、ModelMesh 多命名空间协调、改进的 CloudEvent 和 gRPC 支持以及 KServe v2 REST API 与 TorchServe 集成等功能。
根据发言人的说法,v1.0 的路线图具有稳定的 API,统一了 ModelMesh 和单一模型服务部署以及更高级的推理图功能。
声明:所有白马号原创内容,未经允许禁止任何网站及个人转载、采集等一切非法引用。本站已启用原创保护,有法律保护作用,否则白马号保留一切追究的权利。发布者:白马号,转转请注明出处:https://www.bmhysw.com/article/4961.html
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫 